publications
2026
- TwoSquared: 4D Generation from 2D Image PairsLu Sang*, Zehranaz Canfes*, Dongliang Cao, Riccardo Marin , and 2 more authors(oral) , 2026
Despite the astonishing progress in generative AI, 4D dynamic object generation remains an open challenge. With limited high-quality training data and heavy computing requirements, the combination of hallucinating unseen geometry together with unseen movement poses great challenges to generative models. In this work, we propose TwoSquared as a method to obtain a 4D physically plausible sequence starting from only two 2D RGB images corresponding to the beginning and end of the action. Instead of directly solving the 4D generation problem, TwoSquared decomposes the problem into two steps: 1) an image-to-3D module generation based on the existing generative model trained on high-quality 3D assets, and 2) a physically inspired deformation module to predict intermediate movements. To this end, our method does not require templates or object-class-specific prior knowledge and can take in-the-wild images as input. In our experiments, we demonstrate that TwoSquared is capable of producing texture-consistent and geometry-consistent 4D sequences only given 2D images.
@misc{sang2025twosquared, title = {TwoSquared: 4D Generation from 2D Image Pairs}, author = {Sang, Lu and Canfes, Zehranaz and Cao, Dongliang and Marin, Riccardo and Bernard, Florian and Cremers, Daniel}, year = {2026}, }
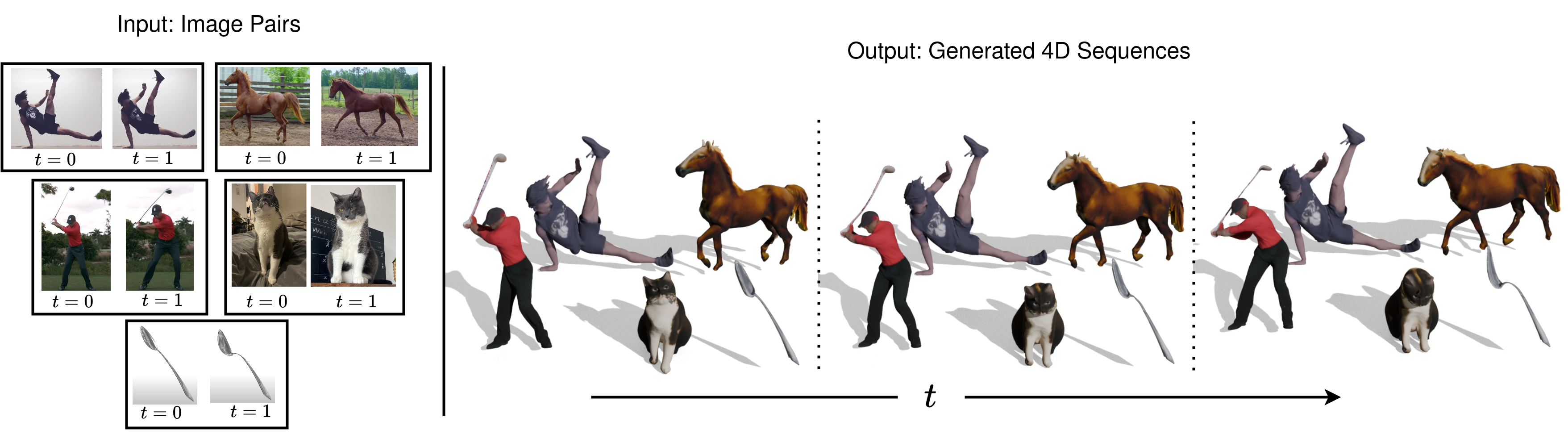
2025
- Beyond Complete Shapes: A Benchmark for Quantitative Evaluation of 3D Shape Matching AlgorithmsComputer Graphics Forum, 2025
Finding correspondences between 3D deformable shapes is an important and long-standing problem in geometry processing, computer vision, graphics, and beyond. While various shape matching datasets exist, they are mostly static or limited in size, restricting their adaptation to different problem settings, including both full and partial shape matching. In particular the existing partial shape matching datasets are small (fewer than 100 shapes) and thus unsuitable for data-hungry machine learning approaches. Moreover, the type of partiality present in existing datasets is often artificial and far from realistic. To address these limitations, we introduce a generic and flexible framework for the procedural generation of challenging full and partial shape matching datasets. Our framework allows the propagation of custom annotations across shapes, making it useful for various applications. By utilising our framework and manually creating cross-dataset correspondences between seven existing (complete geometry) shape matching datasets, we propose a new large benchmark BeCos with a total of 2543 shapes. Based on this, we offer several challenging benchmark settings, covering both full and partial matching, for which we evaluate respective state-of-the-art methods as baselines.
@article{ehm2025beyond, journal = {Computer Graphics Forum}, title = {Beyond Complete Shapes: A Benchmark for Quantitative Evaluation of 3D Shape Matching Algorithms}, author = {Ehm, Viktoria and Amrani, Nafie El and Cremers, Daniel and Bernard, Florian and Xie, Yizheng and Bastian, Lennart and Gao, Maolin and Wang, Weikang and Sang, Lu and Cao, Dongliang and Weißberg, Tobias and Lähner, Zorah}, year = {2025} } - CVPR 25
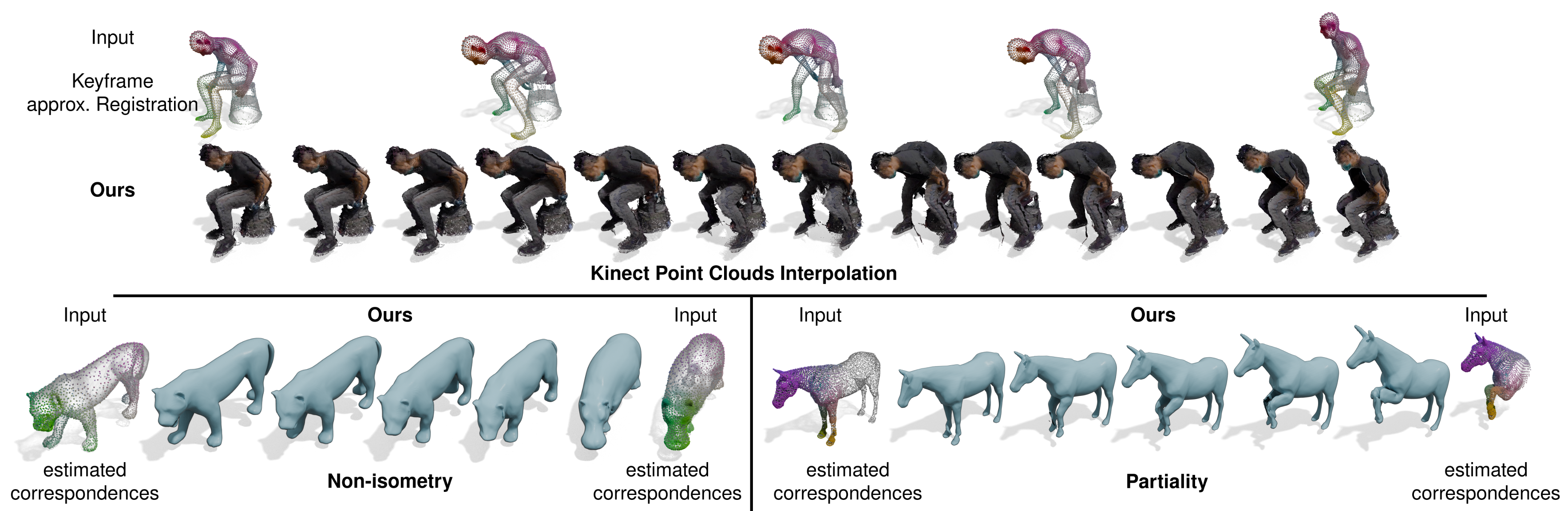 4Deform: Neural Surface Deformation for Robust Shape InterpolationLu Sang, Zehranaz Canfes, Dongliang Cao, Riccardo Marin , and 2 more authorsIn CVPR , 2025
4Deform: Neural Surface Deformation for Robust Shape InterpolationLu Sang, Zehranaz Canfes, Dongliang Cao, Riccardo Marin , and 2 more authorsIn CVPR , 2025Generating realistic intermediate shapes between non-rigidly deformed shapes is a challenging task in computer vision, especially with unstructured data (e.g., point clouds) where temporal consistency across frames is lacking, and topologies are changing. Most interpolation methods are designed for structured data (i.e., meshes) and do not apply to real-world point clouds. In contrast, our approach, 4Deform, leverages neural implicit representation (NIR) to enable free topology changing shape deformation. Unlike previous mesh-based methods that learn vertex-based deformation fields, our method learns a continuous velocity field in Euclidean space. Thus, it is suitable for less structured data such as point clouds. Additionally, our method does not require intermediate-shape supervision during training; instead, we incorporate physical and geometrical constraints to regularize the velocity field. We reconstruct intermediate surfaces using a modified level-set equation, directly linking our NIR with the velocity field. Experiments show that our method significantly outperforms previous NIR approaches across various scenarios (e.g., noisy, partial, topology-changing, non-isometric shapes) and, for the first time, enables new applications like 4D Kinect sequence upsampling and real-world high-resolution mesh deformation.
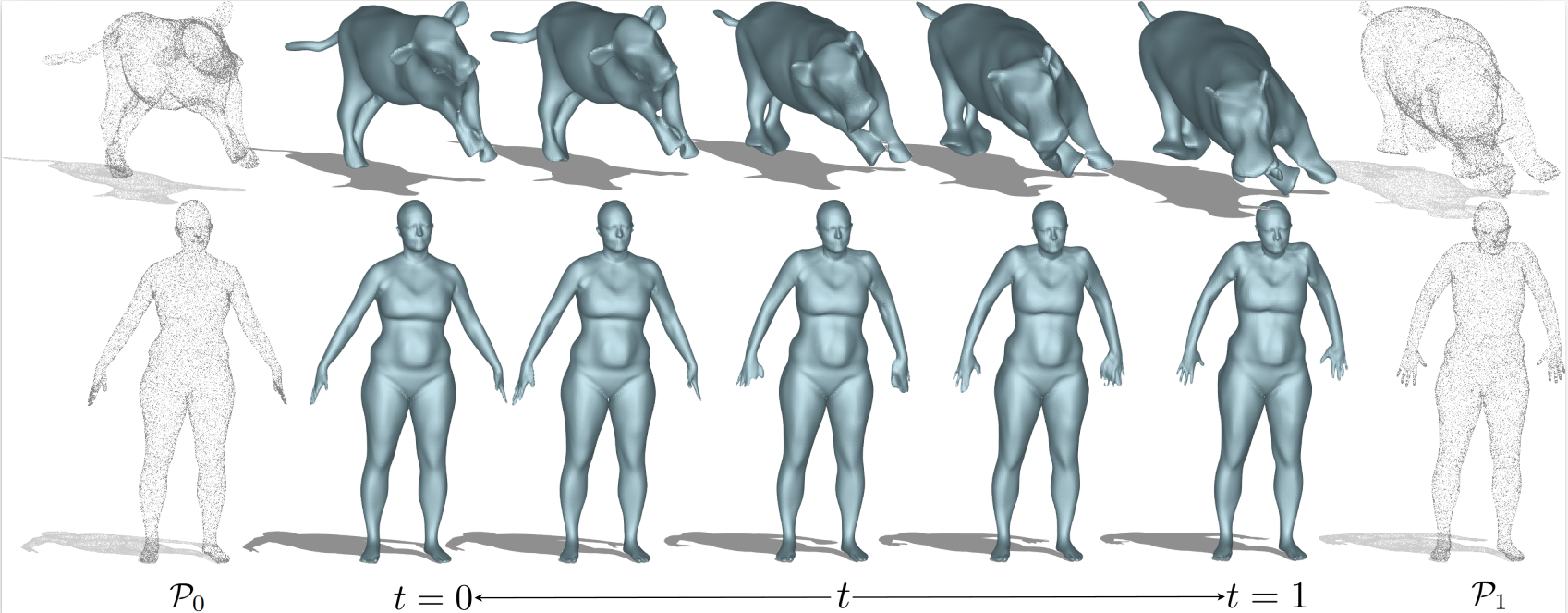
@inproceedings{sang20254deform, title = {4Deform: Neural Surface Deformation for Robust Shape Interpolation}, author = {Sang, Lu and Canfes, Zehranaz and Cao, Dongliang and Marin, Riccardo and Bernard, Florian and Cremers, Daniel}, year = {2025}, booktitle = {CVPR}, } - Implicit Neural Surface Deformation with Explicit Velocity FieldsIn ICLR , 2025
In this work, we introduce the first unsupervised method that simultaneously predicts time-varying neural implicit surfaces and deformations between pairs of point clouds. We propose to model the point movement using an explicit velocity field and directly deform a time-varying implicit field using the modified level-set equation. This equation utilizes an iso-surface evolution with Eikonal constraints in a compact formulation, ensuring the integrity of the signed distance field. By applying a smooth, volume-preserving constraint to the velocity field, our method successfully recovers physically plausible intermediate shapes. Our method is able to handle both rigid and non-rigid deformations without any intermediate shape supervision. Our experimental results demonstrate that our method significantly outperforms existing works, delivering superior results in both quality and efficiency.
@inproceedings{sang2025implicit, title = {Implicit Neural Surface Deformation with Explicit Velocity Fields}, author = {Sang, Lu and Canfes, Zehranaz and Cao, Dongliang and Bernard, Florian and Cremers, Daniel}, year = {2025}, booktitle = {ICLR}, }

2024
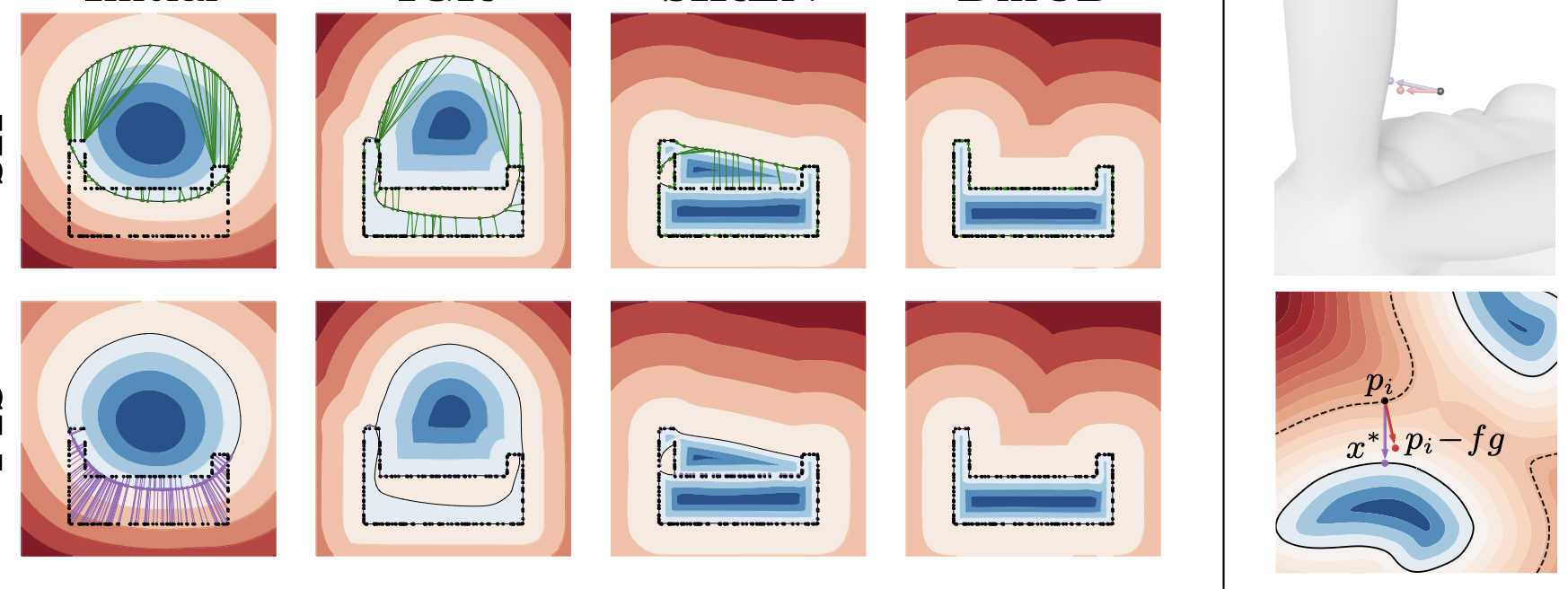
- DiffCD: A Symmetric Differentiable Chamfer Distance for Neural Implicit Surface FittingLinus Härenstam-Nielsen, Lu Sang, Abhishek Saroha, Nikita Araslanov , and 1 more authorIn ECCV , 2024
Fitting neural implicit surfaces to point clouds is typically done by encouraging the network output to equal zero on the point cloud. Yet, since the underlying shape metric is not symmetric, previous methods are susceptible to spurious surfaces. We theoretically analyze the predominant approach for dealing with spurious surfaces, and show that it is equivalent to regularizing the surface area, leading to over-smoothing. We propose a novel loss function corresponding to the symmetric Chamfer distance to address these shortcomings. It assures both that the points are near the surface and that the surface is near the points. Our approach reliably recovers a high level of shape detail and eliminates spurious surfaces without the need for additional regularization. To make our approach more practical, we further propose an efficient method for uniformly sampling point batches from the implicit surface.
@inproceedings{haerenstam2024diffcd, title = {DiffCD: A Symmetric Differentiable Chamfer Distance for Neural Implicit Surface Fitting}, author = {Härenstam-Nielsen, Linus and Sang, Lu and Saroha, Abhishek and Araslanov, Nikita and Cremers, Daniel}, booktitle = {ECCV}, year = {2024}, } - Enhancing Surface Neural Implicits with Curvature-Guided Sampling and Uncertainty-Augmented RepresentationsIn ECCVW , 2024
Neural implicits have become popular for representing surfaces because they offer an adaptive resolution and support arbitrary topologies. While previous works rely on ground truth point clouds, they often ignore the effect of input quality and sampling methods during reconstructing. In this paper, we introduce a sampling method with an uncertainty-augmented surface implicit representation that employs a sampling technique that considers the geometric characteristics of inputs. To this end, we introduce a strategy that efficiently computes differentiable geometric features, namely, mean curvatures, to augment the sampling phase during the training period. The uncertainty augmentation offers insights into the occupancy and reliability of the output signed distance value, thereby expanding representation capabilities into open surfaces. Finally, we demonstrate that our method leads to state-of-the-art reconstructions on both synthetic and real-world data.
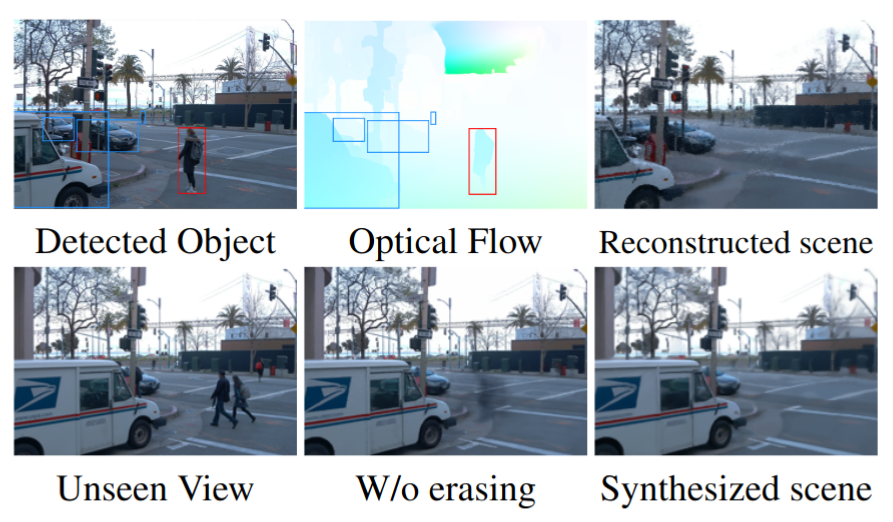
@inproceedings{sang2023enhanching, title = {Enhancing Surface Neural Implicits with Curvature-Guided Sampling and Uncertainty-Augmented Representations}, author = {Sang, Lu and Saroha, Abhishek and Gao, Maolin and Cremers, Daniel}, booktitle = {ECCVW}, year = {2024}, } - Erasing the Ephemeral: Joint Camera Refinement and Transient Object Removal for Street View SynthesisMS. Deka*, Lu Sang*, and Daniel CremersIn GCPR , 2024
Synthesizing novel views for urban environments is crucial for tasks like autonomous driving and virtual tours. Compared to object-level or indoor situations, outdoor settings present unique challenges such as inconsistency across frames due to moving vehicles and camera pose drift over lengthy sequences. In this paper, we introduce a method that tackles these challenges on view synthesis for outdoor scenarios. We employ a neural point light field scene representation and strategically detect and mask out dynamic objects to reconstruct novel scenes without artifacts. Moreover, we simultaneously optimize camera pose along with the view synthesis process, and thus we simultaneously refine both elements. Through validation on real-world urban datasets, we demonstrate state-of-the-art results in synthesizing novel views of urban scenes.
@inproceedings{deka2023erasing, title = {Erasing the Ephemeral: Joint Camera Refinement and Transient Object Removal for Street View Synthesis}, author = {Deka, MS. and Sang, Lu and Cremers, Daniel}, year = {2024}, booktitle = {GCPR}, } - Coloring the Past: Neural Historical Buildings Reconstruction from Archival PhotographyIn ECCVW , 2024
Historical buildings are a treasure and milestone of human cultural heritage. Reconstructing the 3D models of these building hold significant value. The rapid development of neural rendering methods makes it possible to recover the 3D shape only based on archival photographs. However, this task presents considerable challenges due to the limitations of such datasets. Historical photographs are often limited in number and the scenes in these photos might have altered over time. The radiometric quality of these images is also often sub-optimal. To address these challenges, we introduce an approach to reconstruct the geometry of historical buildings, employing volumetric rendering techniques. We leverage dense point clouds as a geometric prior and introduce a color appearance embedding loss to recover the color of the building given limited available color images. We aim for our work to spark increased interest and focus on preserving historical buildings. Thus, we also introduce a new historical dataset of the Hungarian National Theater, providing a new benchmark for the reconstruction method.
@inproceedings{komorowicz2023coloring, title = {Coloring the Past: Neural Historical Buildings Reconstruction from Archival Photography}, author = {Komorowicz, David and Sang, Lu and Maiwald, Ferdinand and Cremers, Daniel}, year = {2024}, booktitle = {ECCVW}, }


2023
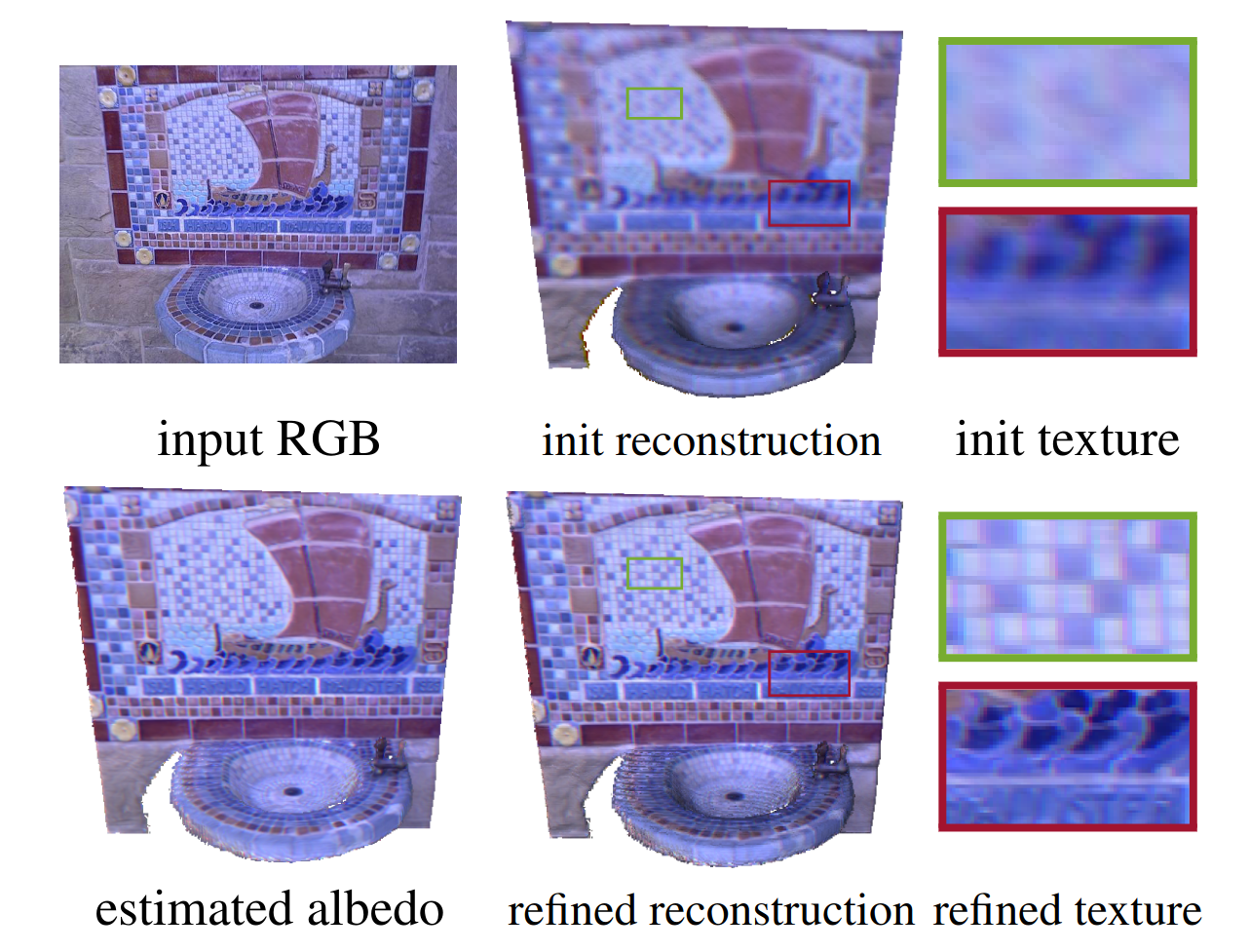
- High-Quality RGB-D Reconstruction via Multi-View Uncalibrated Photometric Stereo and Gradient-SDFLu Sang, Bjoern Haefner, Xingxing Zuo, and Daniel CremersIn WACV (Spotlight Presentation) , 2023
Fine-detailed reconstructions are in high demand in many applications. However, most of the existing RGB-D reconstruction methods rely on pre-calculated accurate camera poses to recover the detailed surface geometry, where the representation of a surface needs to be adapted when optimizing different quantities. In this paper, we present a novel multi-view RGB-D based reconstruction method that tackles camera pose, lighting, albedo, and surface normal estimation via the utilization of a gradient signed distance field gradient-SDF. The proposed method formulates the image rendering process using specific physically-based models and optimizes the surface’s quantities on the actual surface using its volumetric representation, as opposed to other works which estimate surface quantities only near the actual surface. To validate our method, we investigate two physically-based image formation models for natural light and point light source applications. The experimental results on synthetic and real-world datasets demonstrate that the proposed method can recover high-quality geometry of the surface more faithfully than the state-of-the-art and further improves the accuracy of estimated camera poses.
@inproceedings{sang2023high, author = {Sang, Lu and Haefner, Bjoern and Zuo, Xingxing and Cremers, Daniel}, title = {High-Quality RGB-D Reconstruction via Multi-View Uncalibrated Photometric Stereo and Gradient-SDF}, booktitle = {WACV}, year = {2023}, }
2022
- CVPR 2022
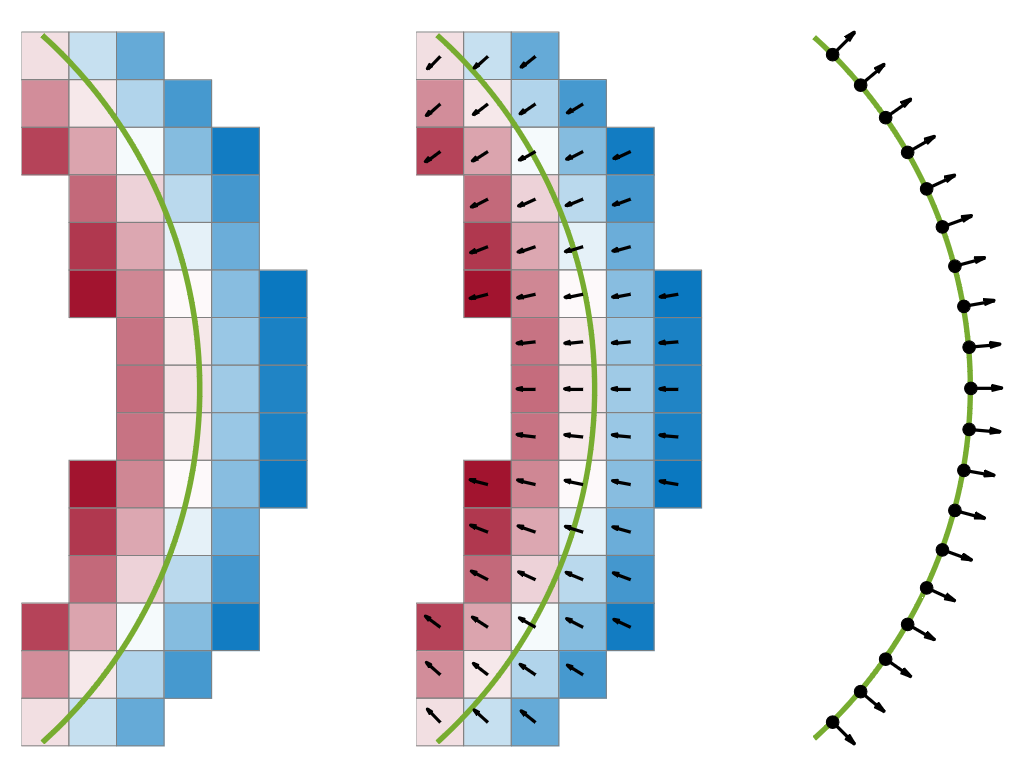 Gradient-SDF: A Semi-Implicit Surface Representation for 3D ReconstructionChristiane Sommer*, Lu Sang*, David Schubert, and Daniel CremersIn CVPR , 2022
Gradient-SDF: A Semi-Implicit Surface Representation for 3D ReconstructionChristiane Sommer*, Lu Sang*, David Schubert, and Daniel CremersIn CVPR , 2022Neural implicits have become popular for representing surfaces because they offer an adaptive resolution and support arbitrary topologies. While previous works rely on ground truth point clouds, they often ignore the effect of input quality and sampling methods during reconstructing. In this paper, we introduce a sampling method with an uncertainty-augmented surface implicit representation that employs a sampling technique that considers the geometric characteristics of inputs. To this end, we introduce a strategy that efficiently computes differentiable geometric features, namely, mean curvatures, to augment the sampling phase during the training period. The uncertainty augmentation offers insights into the occupancy and reliability of the output signed distance value, thereby expanding representation capabilities into open surfaces. Finally, we demonstrate that our method leads to state-of-the-art reconstructions on both synthetic and real-world data.
@inproceedings{Sommer2022, author = {Sommer, Christiane and Sang, Lu and Schubert, David and Cremers, Daniel}, title = {Gradient-{SDF}: {A} Semi-Implicit Surface Representation for 3D Reconstruction}, booktitle = {CVPR}, year = {2022}, titleurl = {sommer2022.png}, }
2020
- Inferring Super-Resolution Depth from a Moving Light-Source Enhanced RGB-D Sensor: A Variational ApproachLu Sang, Bjoern Haefner, and Daniel CremersIn WACV (Spotlight Presentation) , 2020
A novel approach towards depth map super-resolution using multi-view uncalibrated photometric stereo is presented. Practically, an LED light source is attached to a commodity RGB-D sensor and is used to capture objects from multiple viewpoints with unknown motion. This nonstatic camera-to-object setup is described with a nonconvex variational approach such that no calibration on lighting or camera motion is required due to the formulation of an end-to-end joint optimization problem. Solving the proposed variational model results in high resolution depth, reflectance and camera pose estimates, as we show on challenging synthetic and real-world datasets.
@inproceedings{sang2020wacv, title = {Inferring Super-Resolution Depth from a Moving Light-Source Enhanced RGB-D Sensor: A Variational Approach}, author = {Sang, Lu and Haefner, Bjoern and Cremers, Daniel}, booktitle = {WACV}, year = {2020}, }
